When you are running a website used by thousands of people, it should go without saying that very valuable data can be collected about your users and they way they interact with your site. This usually comes in the form of click-stream data – which is effectively logs written by your webserver on every interaction (or click) made by a user who is navigating your site. An e-retailer can use this data for a many purposes, for example: analysing how users interact with the site and what causes them to place an order, monitoring the performance of a new advertising campaign, seeing how users respond to a new feature and detecting problems such as pages which result in an error 404. For many of these purposes, raw data can be crunched through a batch processing system such as Hadoop, but for some purposes it is beneficial have real-time information and statistics about how users are interacting with the site right now.
Imagine you are in e-retailer in the process of rolling out a brand new feature, such an improved search engine. As soon as this feature goes live, it will have an immediate impact on the user experience and the products people are interacting with. It may even change the way people search and the terms they search for. Having real-time statistics such as the number of page views, searches, product visits from searches and product orders from searches gives confidence that the new experience is having a positive impact, or at least not causing any serious problems. This article discusses our experience with building a data store to persist and query over click-stream data in real-time.
For the backing datastore of our analytics framework there were a huge number of possible solutions. We began by considering SQL, but as we are dealing with millions of click-stream events every day SQL can quickly become an expensive and not-so-scalable option. Ultimately we made a choice between MongoDB and Elasticsearch. Both are open source, distributed NoSQL document stores – Elasticsearch is built on top of Apache Lucene (a high performance JVM based search engine) and MongoDB is written entirely in C++. Elasticsearch provides a very clean and compact RESTful API which enables you to use JSON over HTTP to specify your configuration, index documents and perform queries. We found that the query API provided by Elasticsearch provides considerably more flexibility when it comes to faceting and search. An example of this is when you want to calculate a count, total or average and see how it changes over time. For instance, if we want to count the number of searches performed on our site by hour, the date histogram facet makes this easy. The following Elasticsearch query will return a set of key value pairs for each site, where the key is an hourly timestamp and the value is a count of search events:
{
"query": {
"match": {
"eventType": "search"
}
},
"facets": {
"siteId": {
"date_histogram": {
"field": "timestamp",
"interval": "hour"
}
}
}
}
Doing this kind of aggregation with MongoDB is of course possible, but we found these queries are simply quicker and easier to write with Elasticsearch. Plus the API makes it very easy to query the store with a REST client. Of course there are advantages to using MongoDB – for instance at the time of writing there is far more documentation available, MongoDB provides more flexibility as the document structure can be changed at any time and also MongoDB is particularly good at facilitating backup and recovery. Since we were not looking for a primary data store, these advantages didn’t outweigh Elasticsearch’s cleaner API.
One of the first decisions to make when using Elasticsearch is how to structure your indices. In our case, we wanted to capture several different types of events, each of which would have different associated attributes. Page visits, searches, basket adds among other events are all logged by our web servers in real-time. This data then needs to be sent to Elasticsearch and indexed. We decided to use time-based Elasticsearch indices. This means that every day, a new index is created and all data for that day is stored within that index. The index name takes the format ‘EVENT_TYPE-YYYYMMDD’. There are a few advantages to doing this:
- It’s easy to query over only the events and days we want. Elasticsearch supports wildcards matching for the index name – so if we send a query to ‘searches-201401*’ our query will be executed over all the search events which took place in January.
- When we want to delete old data, we simply need to delete old indices. Clearing out old data can then be done easily and automatically using a daily cron job. No need to use time-based indices, which could add significant overhead.
- Routing and sharding can be configured on a per index basis. This makes it possible for us to configure which servers should handle which days. For example, if a server is running out of disk space, we can just configure shards for future indices to avoid that server.
- Using Elasticsearch templates, we can configure a mapping and settings which are automatically applied to new indices. For example, any index created with a name matching ‘searches-*’ will have a specific mapping and settings applied to it.
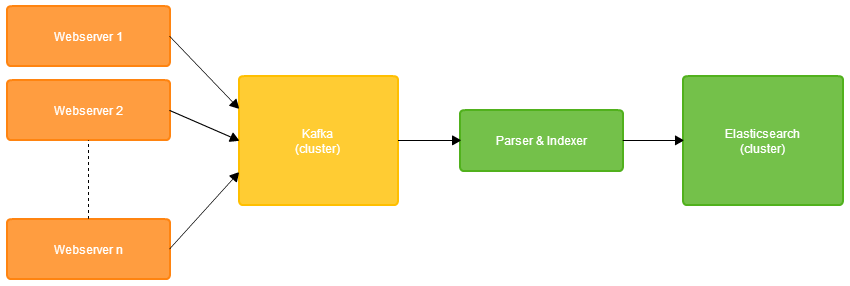
With a good idea of how the data store would be structured, the next step was to get data from our web logs into Elasticsearch, in real-time. This process involves aggregating log files, and then parsing and indexing the log events into Elasticsearch documents. We developed a Java application to serve this purpose – sending bulk updates to our Elasticsearch cluster every few seconds. The simplified data pipeline is pictured below, although we have since replaced log aggregation with Kafka, a distributed messaging framework.
We soon encountered some difficulties when writing queries over our data. One of the biggest difficulties comes when running queries over multiple indices. Each of our event types has different attributes, for example: search terms and search engine information appear on search events, but not on product visit events. What if we want to count the number of product visits resulting from searches for the term ‘xbox’? Well, we want to perform a ‘join’ operation, something which would be quite easy to achieve in SQL:
SELECT * FROM product_visits p INNER JOIN searches s ON (p.userId = s.userId) WHERE p.referrer_url = s.url AND s.term = 'xbox'
With Elasticsearch, things are not so simple. We can easily query several indices at once, but how can we specify that we want to find all product visit documents which have a matching search document?
Solution 1: Use parent child relationships
Elasticsearch enables us to specify a parent child relationship between document types. For instance, we could have two types of document: product_interaction documents (which contain event types product_visit and product_order) and cause documents (which contain event types like search). We could then configure a parent-child relationship between causes and product_interactions, such that each product_interaction is the child of a single cause. This structure enables us to use the built in ‘has_parent’ query to find all product visits that resulted from a specific search:
POST searches-201401*/_search
{
"query": {
"has_parent": {
"parent_type": "cause",
"query": {
"match": {
"searchTerm": "xbox"
}
}
}
}
}
This solution is flexible. The two document types are completely independent of each other – if we want, we can update one without affecting the other. To aid performance, Elasticsearch ensures that children are physically stored in the same shard as their parent. However there is still a performance cost to using the parent child relation and we found that our query speed sometimes suffered. There is also a big limitation to this design – there is no support for more complex relationships, such as grandparent->parent->child. So, we would be unable to add further relationships (e.g. between product_orders and product_interactions) and model the full chain of events.
Solution 2: Add extra information at indexing time
Our end solution which solves both of the above problems is simply to move the logic surrounding relationships into the application layer. State corresponding to recent user activity (for example, searches in the last ten minutes) are stored in memory in our indexing application. Then, when product visit events are received, the in-memory state is checked and the ’cause’ of the product visit can be found. Then, when indexing the product visit document, extra attributes are indexed within the document such as the search terms which led to the product being visited. If we want to track more events in the train, such as product orders, then attributes that were added to the product visit document are copied into the product order document. This means that at query time, we don’t need to search over multiple document types and perform a join – all the information we need is contained in a single document type. This solution gives us very fast query performance at the cost of higher storage and memory requirements – since document size is greater and some information is duplicated.
With this setup, we are able to comfortably query over a month’s worth of data within just a couple of seconds – and that’s with a single node cluster. One problem we encountered is that it is possible to write incorrect or very computationally demanding queries and no matter how complex or demanding the query, Elasticsearch will attempt the computation. If it does not have sufficient resources to complete the query it will fail with an OutOfMemory error and the only way to recover from this is to restart Elasticsearch on the failed node(s). Aside from this, our experience with Elasticsearch for near real-time analytics has been very positive.