Having recently began working for one of Europe’s leading online ad-tech providers, I have been involved in the configuration of a new high-load Kafka cluster with the aim of handling up to 300K messages/second. It really is a high-load requirement – as even LinkedIn, the original developers of Kafka are processing a lower volume, at around 100K messages/second.
One of the choices we faced in setting up the new cluster was centered around how to publish messages from various datacenters around the world. We could either publish to a single Kafka cluster, located in our main datacenter, or we could have a separate Kafka cluster in each region. The network connection between datacenters is slow and potentially unreliable, so it didn’t make sense to publish to a single Kafka cluster from anywhere in the world as there would be a considerable risk of data-loss. For this reason, we wanted to have a separate, local Kafka cluster within each region, but ultimately would need all data to be pushed to our main cluster. In fact, Kafka ships with a tool designed specifically for this purpose – to replicate Kafka topics from one cluster to another. Note that this is not the usual subject of replication in relation to Kafka, which refers to maintaining replicas of Kafka topics within a single cluster for fault-tolerance.
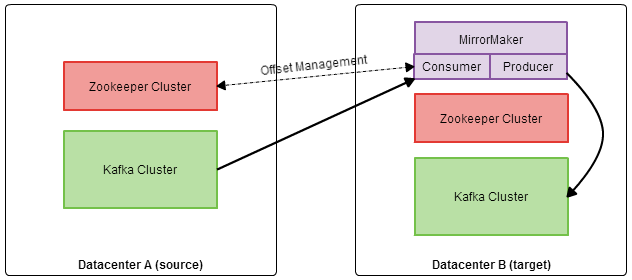
The MirrorMaker tool consists of a consumer and producer. For fault tolerance, multiple MirrorMaker processes can be fired up for the same mirroring task, within the same consumer group. If one fails, consumer re-balancing will take place as usual. The diagram below shows the full picture.
Starting a MirrorMaker process is simple; run the following command from the Kafka installation directory:
bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config config/consumer_source_cluster.properties --producer.config config/producer_target_cluster.properties --whitelist mytopic --num.producers 2 --num.streams 4
Here, the number of consumer and producer threads are specified by the num.streams and num.producers parameters respectively. One thing worth mentioning here is that the topic list parameter accepts a string in the format of a Java regex, so it’s possible to specify topic names with wildcards.
Confirming that the MirrorMaker is keeping up with the volume of messages in the source cluster’s topics can be done by running the built in offset checker and checking that the offset lag for each partition is not growing indefinitely:
bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zkconnect zookeeperhost:2181 --group mirrormaker
There is a possibility of data loss when using the MirrorMaker – in the case where the producer is unable to produce messages and the consumer is still able to consume. This could occur if there were a network outage which only affected the producer. In this scenario, the consumer will continue to consume messages and commit offsets. This will likely be for a short period of time as the MirrorMaker exits upon an exception in either the consumer or producer threads, but those messages consumed and not produced are lost. There is a plan to address this issue which has been accepted for the next Kafka release.
There are a few settings that can be tweaked, such as the number of consumer and producer threads, the number of MirrorMaker processes and the properties for both the consumer and producer. In the producer properties, the queue.enqueue.timeout.ms should be set to -1 to cause the producer to block indefinitely if its queue queue is full – this can help to prevent data loss in the scenario described above. I ran some tests to investigate how the configuration affects the mirroring throughput. In these tests, the MirrorMaker processes ran in the target datacenter – which seems a sensible choice given the data-loss scenario. Failure between consuming and producing should be less likely if the cross-datacenter network transfer has already taken place before producing takes place. Here were the results:
| Processes | Consumer Threads | Producer Threads | Maximum Throughput |
|---|---|---|---|
| 1 | 6 | 2 | 6 MB/s |
| 1 | 12 | 2 | 10 MB/s |
| 1 | 18 | 2 | 10 MB/s |
| 2 | 12 | 2 | 14 MB/s |
| 2 | 12 | 4 | 19 MB/s |
| 3 | 12 | 6 | 24 MB/s |
| 3 | 12 | 8 | 29 MB/s |
In this investigation, the source topic had 12 partitions and we found that for maximum parallelism, the total number of consumer threads across all mirroring processes should add up to the total number of partitions. Since partitions are the unit of parallelism in Kafka, this rule applies to any type of Kafka consumer. We found that if the number of producer threads too low, this can be a bottleneck – this is shown by the difference in throughput between the fourth and fifth tests. We can also see that throughput scales fairly linearly with the number of MirrorMaker processes and consumer threads.
In conclusion, the MirrorMaker tool is a convenient solution to dealing with multiple Kafka clusters in different physical locations, when you want all data to be mirrored to a ‘main’ Kafka cluster. The number of MirrorMaker processes should be high enough to handle failure and the number of consumer and producer threads within these processes can be tweaked to achieve a target throughput. There is a data-loss scenario in the current version of MirrorMaker, but the probability of data-loss can be minimised by running MirrorMaker in the target datacenter.
I’m working on a project by which we use to transfer events from Amsterdam datacenter to Chicago datacenter. Our traffic is up to 30k messages/sec (400Bytes per events).We found we lost some events, around 1-2%. Could you give me some hints or share your configurations for the consumer and producer? Thank you very much!
Hi Jason, I don’t believe we ever experienced data loss like that – the MirrorMaker tool is just a basic consumer and producer so any data loss is likely caused by a network issue. Is the rate of dropped messages fairly constant over time, or does it happen in bursts? Also are you running the MirrorMaker process in the target datacenter? If you are running in the source datacenter, I guess it could be an intermittent network outage affecting the producer and you might be seeing the data-loss scenario described in the post. But if you are running MirrorMaker in the target datacenter then that shouldn’t happen!
Thank you for your reply. Just from 5:00AM this morning (EDT), my mirror makers are working fine. My mirror makers are deployed at the target data center (Chicago), just before the weekend, the transfer rate was slower than the message producer in source data center (Amsterdam). But from 12PM yesterday, the Mirror Maker started to work at a very high speed and from 5:00AM, it moved all data accumulated at Amsterdam to Chicago and is working at the same rate that Amsterdam produces events. About the data loss, it’s not “data loss” but just was accumulated and not transferred successfully..
Thank you again.
Hi,
Thanks for the post. Have a question though.
The load is 300k msg/sec and the highest through-put is 29 MB/sec. What is the size of each message?
Sorry for the late reply! In these tests, the messages were around 100 bytes each on average. We were using protocol buffers for serialization to keep the message size down.
Hi! You might want to update the numbers about LinkedIn:
From https://engineering.linkedin.com/kafka/running-kafka-scale :
“At the busiest times of day, we are receiving over 13 million messages per second”
we are planning to set up cross-datacenter-mirroring as well.
I meant to ask how you deal with topic names.
If there is one logical topic named “A” that you have in several regions (US, EMEA, APAC). Do you name the Kafka topics “A_us”, “A_emea”? So, would the topics be per region and after the replication a target datacenter (for example US) would have its local A_us topic and the replicated A_apac and A_emea topics?
Is this how one would to it or is there a way to keep the topic names the same across regions?
Thanks
Sascha
Hi Sascha,
Actually for us, we didn’t need the aggregate/master topic in each data centre. We only needed the aggregate topic in one data centre, where all our consumers were running. So we were able to use the same topic name in each region, but only one region had the aggregated data from all other regions. If you need the aggregated data in every region then I think you’d need to do as you suggested and have (in each region) a regional topic which producers write to, and an aggregate topic which consumers read from. It would be good to hear if you come up with a different solution though!
Josh
We are using kakfa mirror-maker to replicate kakfa between two data centers. Kafka have 15 topics with 5 partitions each. Mirror-maker have 5 producers and 5 streams and queue.enqueue.timeout.ms=-1 and its running on target data center. The normal lag offsets between source and target kafka is less than 1k. But sometimes we are getting huge lags(more than 100k) for some topics and it is taking few hours to get stabilised. Its working fine for other topics with same load. Can you please help to identify the issue?
Hi,
Is it possible to run the mirror maker on a broker which is not part of the target cluster?
My use case is to mirror the production cluster load on to a test cluster. And the brokers in the target cluster will be replaced one after the other so I don’t want the mirroring to stop during the test.
Thanks in advance!
I just tried it out and it worked.
Nice article. Thanks. You may want to update the article with more recent happenings since the ticket has been closed and Kafka released. Is it all now working perfectly for you since the release or was the fix imperfect revealing further issues?
JIRA: KAFKA-1997
Released: 0.8.3
Thanks for sharing. How did you address security?
How did you secure the replication and set up networking?