I was first exposed to parsers when studying compilers at university – I built something that could take a program written in a fictional programming language as input and produce runnable assembly code as output. It was interesting and fun, but I doubted I would ever use the knowledge in industry. When the need came up for a ‘language’ that non-technical people could use to construct Elasticsearch queries, I realised that a custom built parser would be the ideal solution.
We were using Elasticsearch to power our sites’ search functionality and product list pages. The list pages would be created by non-technical site managers and to avoid the inflexibility of manually specifying a list of product IDs we wanted them to instead be able to write a search query which would result in the list page being built dynamically. For example, a list page for mens shampoos and conditioners which have been reduced to half price or less might be represented by the below ‘list definition’, which describes how to query the product index:
content_gender:male AND content_category:(shampoo OR conditioner) AND price_discount_multiplier: [0 TO 0.5]
Elasticsearch actually has a query type, called the query string query, which uses a built-in query parser to build queries from a simple language with very similar structure to the above. However, we had some very specific requirements, such as being able to elevate certain products under certain conditions (i.e. enabling the list to have some manual ordering which may override the ordering of the results returned by the search engine). So, it became clear that we would need to invent our own query parser.
There are a number of frameworks available for building parsers. Two popular choices are ANTLR and JavaCC (Java Compiler Compiler). ANTLR has been around for a long time and provides the most features – it is especially appropriate for more complex tasks such as building an actual program compiler. JavaCC is simpler and, as its name implies, targets the Java language and provides the most familiarity for Java developers. Since the systems powering our websites are written in Java, JavaCC seemed like the right choice.
The first step in building a parser is to write a grammar. A grammar defines the syntax of our language and is used for syntax analysis; in our case this involves going through a list definition, ensuring that it syntactically makes sense and simultaneously building a data structure which we can later use to generate an Elasticsearch query. For our language, the data structure that we want to build is called an abstract syntax tree (AST) – a tree representation of our syntax. For example, the syntax tree for the list definition content_gender:male AND content_category:(shampoo OR conditioner) would look like this:
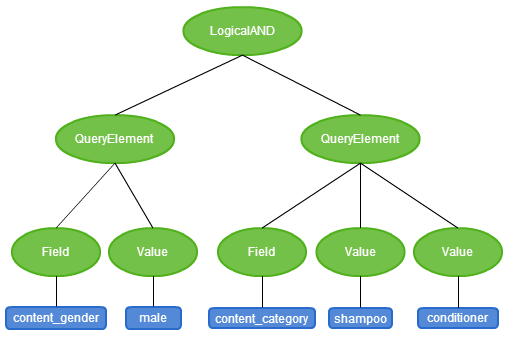
To build this tree, we can use JJTree, an extension for JavaCC which will build the AST data structure for us, and will enable us to describe how the tree should be built within our grammar. The grammar itself is fairly straightforward to write, once you get used to the syntax. Firstly, we define all the tokens (i.e. strings) which we want our parser to be able to consume:
TOKEN :
{
< AND : "AND" >
| < OR : "OR" >
| < LBRACKET : "(" >
| < RBRACKET : ")" >
| < COLON : ":" >
| < WORD : ["a"-"z", "*", "_"]* >
... etc
}
Next, we define the parsing rules, which describe how the parser should consume these tokens and how the AST should be built. JJTree extends the grammar syntax so that we can use #NodeName to indicate that a node should be added to the syntax tree whenever the parser consumes the corresponding tokens. Below is a simplified example of what the rules will look like. These rules will support a language which consists of the AND and OR logical operators and grouping with brackets. Note that the rules are recursive: a query consists of sub queries, which can consist of more queries. We can also extract tokens such as the field names and values and store them as in the generated syntax tree. This is done by assigning the token value to a field defined within the node.
ASTQuery query() #Query:
{
Token t;
}
{
subQuery()
(
< AND > subQuery() #LogicalAnd(2)
| < OR > subQuery() #LogicalOr(2)
)*
{
return jjtThis;
}
}
void subQuery() #void:
{
boolean not = false;
}
{
< LBRACKET >query()< RBRACKET >
| queryElement()
}
void queryElement() #QueryElement:
{}
{
(
LOOKAHEAD(2) field() < COLON > ( value() | valueList() )
| vstring()
)
}
void field() #Field:
{
Token t;
}
{
t = < WORD >
{
jjtThis.value = t.image;
}
}
void valueList() #void:
{}
{
< LBRACKET > value() (< OR > value())* < RBRACKET >
}
void value() #Value:
{
Token t;
}
{
(
< QUOTE >t=< STRING >< ENDQUOTE >
| t=< WORD >
)
{
jjtThis.value = t.image;
}
}
Having defined the rules, we can use JavaCC to generate classes for each node and compile our parser which will do all the work needed to convert list definitions written in our language into syntax trees. Now comes the interesting part – turning these syntax trees into Elasticsearch queries which can be ran against our index. To do this, we need to traverse the abstract syntax tree and construct a query. For traversal, JJTree provides support for the visitor design pattern. For building the query, we can use the Elasticsearch Java API.
To use the visitor pattern, we must ensure that the JJTree option VISITOR=true is set. This flag causes JJTree to generate a visitor interface which we can implement, and also adds a jjtAccept() method to the generated node classes. We can then write a visitor class which implements the generated interface. For each node, we implement visit method which describes how to behave when we encounter each specific type of node. For example, when we reach a LogicalAND node, we can use the Elasticsearch Java API to create an AndFilterBuilder, and populate it with filters retrieved from the child nodes. We can retrieve these filters by calling the accept methods on the node’s children. At each level in the tree, we return an Elasticsearch query or filter object to the caller which can be composed into other queries further up the tree.
Here’s an example of what the visit methods could look like for the Query (root), LogicalAnd and QueryElement nodes:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
@Override public Object visit(ASTQuery node, Object data) { Object result = node.jjtGetChild(0).jjtAccept(this, null); return filteredQuery(matchAllQuery(), (FilterBuilder) result); } @Override public Object visit(ASTLogicalAnd node, Object data) { if (node.jjtGetChild(0) instanceof ASTLogicalAnd) { AndFilterBuilder fb1 = (AndFilterBuilder)(node.jjtGetChild(0).jjtAccept(this, null)); FilterBuilder fb2 = (FilterBuilder)(node.jjtGetChild(1).jjtAccept(this, null)); return fb1.add(fb2); } else if (node.jjtGetChild(1) instanceof ASTLogicalAnd) { AndFilterBuilder fb1 = (AndFilterBuilder)(node.jjtGetChild(1).jjtAccept(this, null)); FilterBuilder fb2 = (FilterBuilder)(node.jjtGetChild(0).jjtAccept(this, null)); return fb1.add(fb2); } else { FilterBuilder fb1 = (FilterBuilder)(node.jjtGetChild(0).jjtAccept(this, null)); FilterBuilder fb2 = (FilterBuilder)(node.jjtGetChild(1).jjtAccept(this, null)); return andFilter(fb1, fb2); } } @Override public Object visit(ASTQueryElement node, Object data) { if (node.jjtGetNumChildren() == 2) { // QueryElement is a field-value pair String field = ((SimpleNode)(node.jjtGetChild(0))).value.toString(); String value = ((SimpleNode)(node.jjtGetChild(1))).value.toString(); return termFilter(field, value); } else if (node.jjtGetNumChildren() > 2) { // QueryElement is a field with a list of possible values (logical OR query) String field = ((SimpleNode)(node.jjtGetChild(0))).value.toString(); OrFilterBuilder orfb = orFilter(); for (int i = 1; i < node.jjtGetNumChildren(); i++) { String value = ((SimpleNode)(node.jjtGetChild(i))).value.toString(); orfb.add(termFilter(field, value)); } return orfb; } return FilterBuilders.matchAllFilter(); } |
To test this, we can just use the parser to generate a tree and pass an instance of our visitor class to the root node to generate a query.
|
1 2 3 4 5 |
DDLParser parser = new DDLParser(new java.io.StringReader(str)); ASTQuery root = parser.run(); ElasticSearchQueryVisitor esv = new ElasticSearchQueryVisitor(); QueryBuilder qb = (QueryBuilder)(root.jjtAccept(esv, null)); System.out.println(qb.toString()); |
That’s it! We now have a parser that can take input written in our custom-built query definition language, turn valid syntax into a syntax tree and finally build an Elasticsearch query.