The ability to do A/B testing has become a key requirement of many tech driven companies. Without the ability to run meaningful A/B tests, how can we know for sure that changes and new features are resulting in the improvements that we anticipate? Here are a few examples of how A/B testing is used:
- A social network, changing the number of required fields on their registration webpage and monitoring how it affects the percentage of visitors who register
- An e-retailer, making a change to the way products are ordered by an e-commerce search engine and monitoring how it affects the number of product orders attributed to search
- An advertiser, comparing statistical models used in placing advertisements and seeing which model leads to the highest click-through rate
In fact, any product which involves user interaction can be A/B tested to ensure that changes or new features are having a positive effect on relevant key performance indicators (KPIs).
In this post, I will discuss the motivation and benefits of implementing A/B testing as a generic service, to be shared and used throughout an organisation.
Consider the most simplistic implementation of A/B testing.
This will typically involve splitting the users of an application into two equal halves and then giving each of the two user groups a different experience. This could be achieved by adding some simple logic inside your application:
|
1 2 3 4 5 |
if (hash(user_id) % 2 == 0) { //turn on new feature } else { //turn off new feature } |
Here, we take the integer hash code of a user’s ID and apply modulo 2. Then, if we get an even number, give the user experience A and if we get an odd number, give the user experience B. We can store or log the experience given to each user and later compute some KPIs for the ‘odd’ users and the ‘even’ users and compare the two user groups.
This implementation should work fine, but in practice, there are a number of other things that are usually required from an A/B testing framework:
-
Be able to disable a live experiment, or change the traffic allocation.
For example, you might want to give just 1% of users a new feature and verify that it’s working as expected before ramping the traffic allocation up to a 50/50 test. In our simple implementation, the traffic allocation is hard-coded into the application, so we’d have to redeploy every time we make a change. Of course, we could use a database to store experiment configuration and make it possible to change the configuration while the application is running, but this is a lot more work to implement and requires you to maintain a database.Another concern here is around how you later perform your KPI analysis. Imagine a traffic allocation change being made to a live A/B test, at a certain point in time:

Scenario where a traffic allocation change is made to a live A/B test.
When you perform KPI analysis to compare your experiments, it’s acceptable to perform the analysis before the change was made, or after the change was made, but not across the time of the change. This generally applies to any type of change – changes will affect your KPIs in some way and your results will not be meaningful if you analyse your experiments across the time when a change was made. It would be good if our A/B testing logic had some way of enforcing meaningful analysis. -
Have experiments with multiple parameters.
In example above, there is just one parameter: a boolean indicating whether the new feature should be turned on or off. But it’s possible that you might want to have an experiment with many parameters, and these parameters may have different types. Hard-coding these parameters into your application will quickly become messy and hard to organise. -
Have multiple experiments running at the same time.
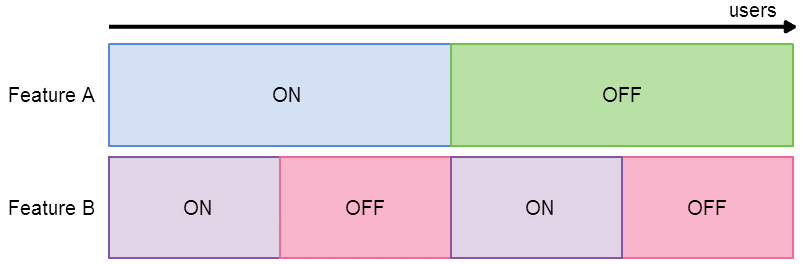
Things can get tricky when you want to run multiple experiments at the same time. When is it OK for a user to be in two experiments at once? Of course, if you have several experiments testing the same thing (such as in the advertiser use case mentioned earlier, where there are several statistical models and you want to find which one yields the highest click-through rate), then a user can only be in one of those experiments. On the other hand, if you have two unrelated experiments which are testing completely independent features, then it’s fine for a user to be in both experiments at the same time.There are further complexities around how to allocate traffic fairly when users are being assigned to multiple experiments. Consider the case where we are A/B testing two new, independent features. For each feature, we want to find out whether it’s better to have that feature enabled or disabled. The scenario is depicted in the below image:
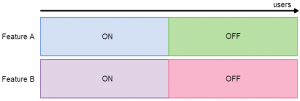
A/B testing two independent experiments simultaneously, with an unfair traffic allocation scheme. Here, if you imagine that users are distributed horizontally across the diagram, then drawing a vertical line anywhere on the diagram would represent a single user’s experience. Here, if a user is assigned the experiment Feature A: On, they will also be assigned Feature B: On. So, if we later analyse the KPIs for the purple users vs the red users, we will have no idea whether any change in the KPIs has come from Feature A or Feature B. We need to allocate traffic in a fair way:
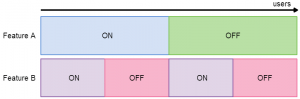
A/B testing two independent experiments simultaneously, with a fair traffic allocation scheme. Here, the users assigned Feature A: On are equally split over Feature B: On and Feature B: Off. Now, if we look at the KPIs for the purple users vs the red users, we know that any change we see is purely down to Feature B.
In this example, the solution is quite obvious, but what if we are testing many more features simultaneously – some of which have more than two variations. We need a way to ensure traffic is always allocated fairly, in any situation.
-
Introduce segmentation logic.
This is where you want your experiments to behave differently depending on the situation. For example, you might want an experiment to only be applicable to users from a certain country. Again, if you are writing your own A/B testing logic, this is more work for you to implement in your application. -
Validate experiments before they go live.
In particular, this applies in the case where your experiments have many parameters of different types. There’s always the possibility of human error when you are configuring or making changes to an experiment. It would be nice to have a way to validate experiment configuration and ensure we are setting the right parameters with the correct types.
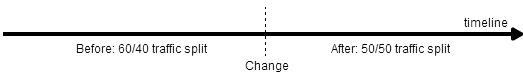
Implementing all of these features is a lot of work – and certainly not something you want to repeat in every application you develop that has some form of A/B testing requirement. A nice solution is to build an A/B testing service which handles things like storing experiment configuration, validation, segmentation, running multiple experiments simultaneously and allocating traffic fairly. Such a service could be used in two ways:
- By people: to define, configure and manage experiments
- By an application: to retrieve a set of parameters for handling a specific request
This can be hugely beneficial for anyone building an application that wants to do A/B testing. Instead of implementing a load of A/B testing logic in your application, your application just needs to make a single call to a service – effectively asking the question ‘what experience should I give this user?’. With this design, a client application just needs to pass a userId (or some other data element to use to split traffic into experiments) and a set of attributes which may be used for segmentation (for example, country=denmark might be an attribute). The client will then receive a response with a set of parameters which it can use to determine what experience to give the user. Using our earlier example, the response parameters would consist of something like featureEnabled=true. No other A/B testing logic needs to be implemented in the application itself!
Having a generic A/B testing service clearly brings many benefits when you have multiple applications that need this type of functionality. But, there is a notable drawback to the scheme described above which I came across when building an A/B testing service to be used in my organisation. This design assumes that it is feasible to make a request to a separate service for every request processed by the application. There are two potential issues with this assumption: the first being that in super-low latency applications, adding a couple of milliseconds to the response time may be unacceptable, and the second being that in high-load applications, the volume of requests may be too high for it to be feasible to call an external service on every request.
We hit the second issue – as we have an application which handles hundreds of thousands of requests per second and it wasn’t feasible to give the A/B testing service enough resource to handle that kind of volume. Our solution was to allow this application to download experiment traffic allocation instructions periodically from our service and implement some additional A/B testing logic in the application. This solution is not as clean as the call-on-every-request approach as it requires more work in the client application, such as segmentation logic, but the application still benefits from the service handling configuration storage, validation and traffic allocation.
For a more detailed description of the logic behind handling multiple simultaneous experiments, check out my next post (originally published on the Adform engineering blog). I also recommend reading this paper from Google, which the ideas in this post are based on.